
Next.js hat kürzlich (in Version 12.2) ein neues Feature stabilisiert: On-Demand Incremental Static Regeneration. Damit soll es möglich sein, veraltete statisch generierte Seiten genau dann zu invalidieren, wenn sich die zugrunde liegende Inhaltsquelle ändert.
Mein aktuelles Projektteam bezieht Inhalte von einem Headless CMS und betreibt Next.js auf einem automatisch skalierenden Container-Dienst. Derzeit verwenden wir Incremental Static Regeneration mit einem festen Intervall und haben in Erwägung gezogen, stattdessen On-Demand ISR zu nutzen. Dabei sind einige Probleme aufgetaucht, die wir glücklicherweise noch vor dem Release entdeckt haben.
Hintergrund
Static Rendering ist eines der zentralen Features von Next.js. Für Seiten, bei denen dieses Feature aktiviert ist, ruft Next.js die benötigten Daten ab (durch Ausführen von getStaticProps) und rendert die Seite bereits zur Build-Zeit vor.
Incremental Static Regeneration (ISR) erweitert dieses Konzept auf Seiten, deren Pfade zur Build-Zeit noch nicht bekannt sind – z. B. wenn ein neuer Blogbeitrag erstellt wird und ein Benutzer ihn aufruft. In diesem Fall kann Next.js die Daten bei Bedarf abrufen, den Inhalt rendern und für zukünftige Anfragen zwischenspeichern. Es ist möglich, ein Intervall anzugeben, nach dem Next.js den Inhalt automatisch neu erstellt.
On-Demand ISR ist eine API, mit der der gecachte Inhalt manuell invalidiert werden kann. Mit diesem Feature kann das Backend, z. B. ein CMS, einen Webhook aufrufen, um Seiten sofort neu zu erstellen, sobald sich der Inhalt ändert – anstatt
bei jeder Inhaltsänderung einen vollständigen neuen Build auszulösen oder
auf das Ablaufintervall der Revalidierung zu warten, bis der neue Inhalt online geht.
Dies funktioniert durch das Einrichten einer API-Route, die den entsprechenden Inhalt invalidiert:
// /pages/api/revalidate.ts
export default function handler() {
// do some authentication here
revalidate()
}Self-hosted Next.js
Viele unserer Kunden betreiben Next.js auf einer automatisch skalierenden Container-Plattform. Typische Kandidaten dafür sind:
Kubernetes-basierte Deployments
Google Cloud Run
AWS Fargate
fly.io
Diese Plattformen funktionieren ähnlich: Sie starten einen Container, der die eigentliche Next.js-Instanz ausführt. Die Plattform überwacht dann automatisch die Ressourcenauslastung des Containers und startet bei Bedarf weitere Instanzen, z. B. wenn Metriken wie Speicher- oder CPU-Auslastung einen bestimmten Schwellenwert überschreiten. Anfragen werden über einen Load Balancer verteilt, der automatisch eine passende Instanz für jede Anfrage auswählt.
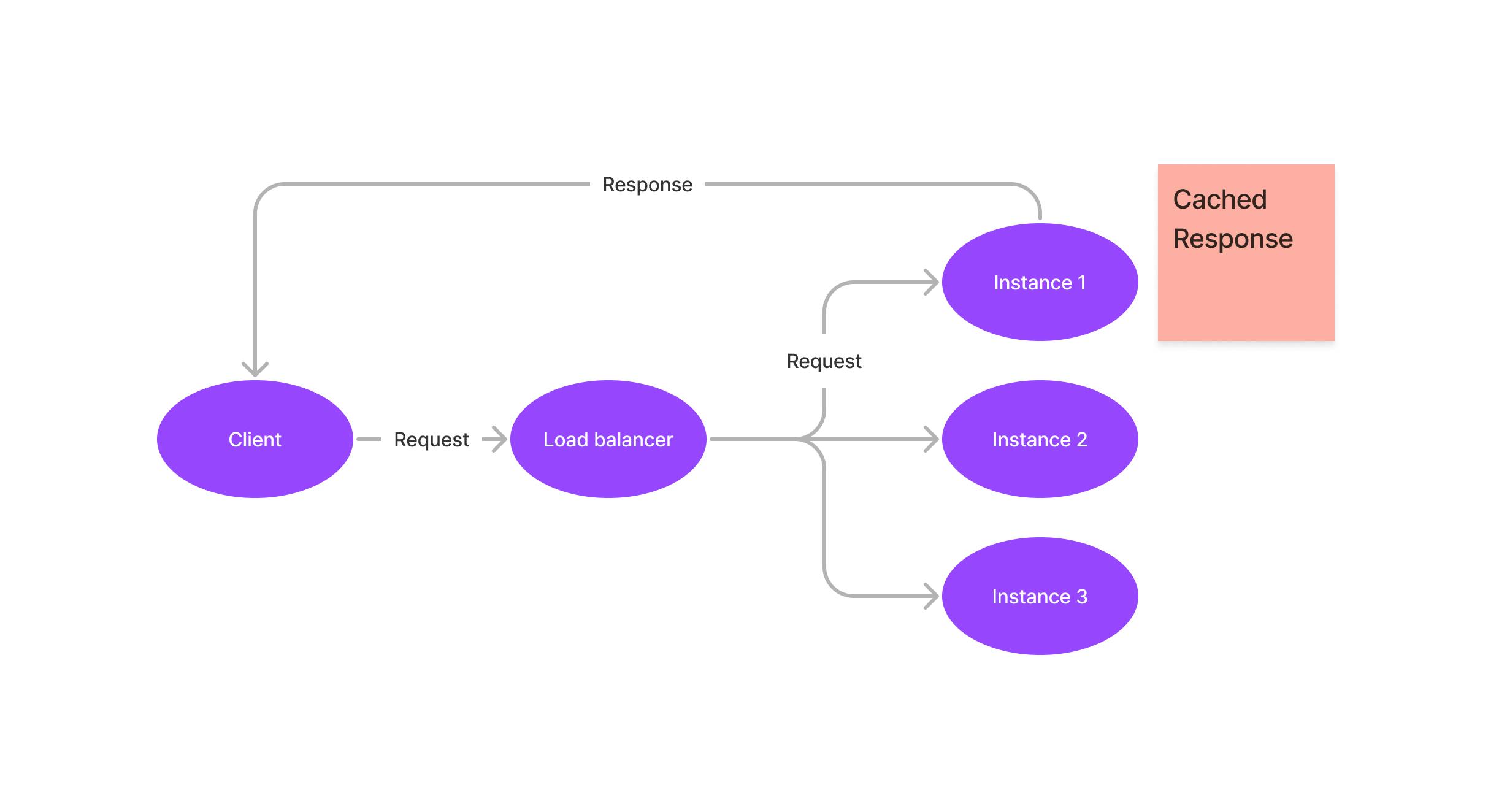
Das Problem
Die Daten aus ISR werden im lokalen Speicher und/oder im Dateisystem jedes Containers gespeichert.
Eine Invalidierungsanfrage von der Inhaltsquelle an /api/revalidate wird – wie jede andere Anfrage – über denselben Load Balancer geleitet und erreicht daher genau eine der laufenden Instanzen.
Das bedeutet, dass die Invalidierung nur den lokalen Cache dieser einen Instanz betrifft – alle anderen Container behalten weiterhin eine veraltete Version der Seite bei.
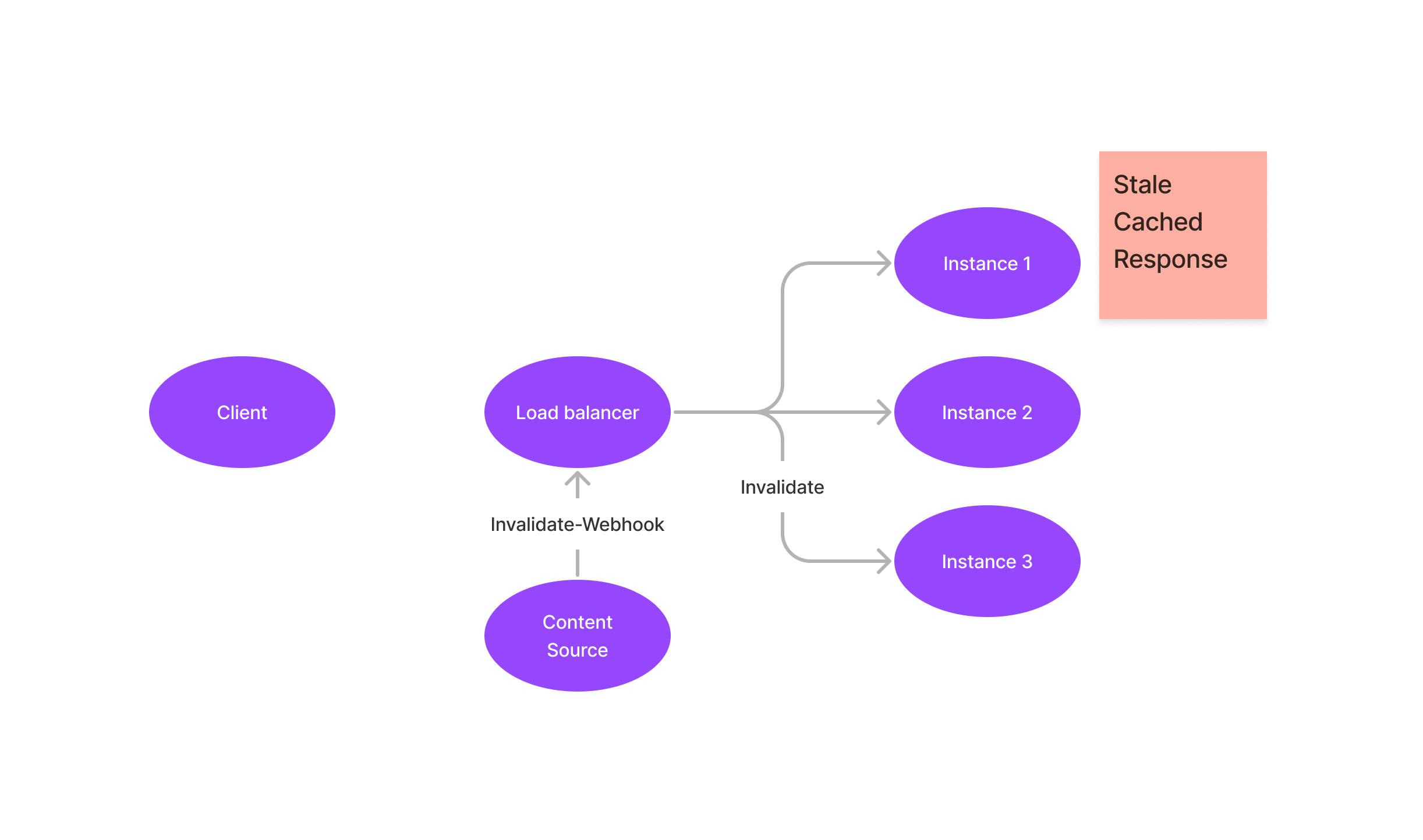
Abmilderung
Um dieses Problem zu vermeiden, gibt es mehrere Strategien:
Einen Weg finden, Revalidierungsanfragen an alle Container zu senden, nicht nur an einen einzelnen. Soweit ich weiß, ist das bei Deployments auf Cloud Run und Fargate zumindest nicht trivial umzusetzen. Zudem bringt dieser Ansatz eigene Herausforderungen mit sich – z. B. was passiert, wenn eine Instanz zum Zeitpunkt der Invalidierung vorübergehend nicht erreichbar ist.
Container austauschen, anstatt nur den Cache zu invalidieren. Das dauert etwas länger und erfordert eine Interaktion mit dem Container-Orchestrierungssystem, funktioniert aber zuverlässig.
Stattdessen auf Revalidierungsintervalle setzen und damit leben, dass es einen Moment dauert, bis aktualisierter Inhalt online ist – und dass Container Seiten eventuell ein paar Mal öfter als nötig neu rendern müssen.
Zusammenfassung
In automatisch skalierenden Umgebungen treffen Invalidierungsanfragen in der Regel nur eine der aktiven Instanzen.
Die Verteilung einer Invalidierungsanfrage an eine unbekannte Anzahl laufender Instanzen ist schwierig.
Meine Empfehlung: Verwende bei ISR auf auto-skalierender Cloud-Infrastruktur lieber Revalidierungsintervalle, da sie eine nahtlose Nutzererfahrung bieten (durch stale-while-revalidate-Caching) – ohne die Komplexität einer verteilten Cache-Invalidierung.